K8s 安全资源
安全资源
Kubernetes(k8s)提供了一些安全资源来增强集群的安全性和保护应用程序的机密信息。
认证机制
API 服务器可以配置多个认证插件。API 接收到的请求会经过一个认证插件列表,列表中的每个插件都可以检查这个请求和请求发送者身份。如果列表中有插件可以提取客户端的用户名、用户 ID 和组信息,则停止调用剩余的认证插件,将已经认证过的用户的用户名和组(可能有多个组)返回给 API 进入授权阶段。否则,返回 401 响应状态码。
可以通过在 API 服务器启动时加入选项来开启认证插件。目前可以使用的认证方式有:客户端证书、传入在 HTTP 头中的认证 token、基础的 HTTP 认证。
用户
k8s 区分两种连接到 API 服务器的客户端:用户和 pod(pod 中的应用)。这两种类型的客户端都使用认证插件进行认证。
用户应该被管理在外部系统中,例如单点登录系统(SSO)。不能通过 API 服务器创建、更新或删除用户。
pod 使用一种称为 Service Accounts 的机制,该机制被创建和储存在集群中作为 ServiceAccount 资源。
组
正常用户和 ServiceAccount 都可以属于一个或多个组,组用来给多个用户赋予权限。系统内置的组有一些特殊含义:
-
system:unauthenticated:分配给所有认证插件都无法认证的客户端。 -
system:authenticated:自动分配给成功通过认证的用户。 -
system:serviceaccounts:包含所有系统中的 ServiceAccount 对象。 -
system:serviceaccount:<namespace>:包含特定命名空间中的所有 ServiceAccount 对象。
安全上下文
可以在 pod 或其所属容器的描述中通过 security-Context 选项配置其他与安全性相关的特征。可以用于整个 pod 或 pod 中单独的容器。
其主要可以达到以下目的:
-
指定容器中运行进程的用户(用户 ID)。
-
阻止容器以 root 用户运行(容器默认运行用户通常在镜像中指定,需要阻止容器以 root 用户运行)。
-
使用特权模式运行容器,使其对宿主节点的内容具有完全的访问权限。
-
通过添加或禁用内核功能,配置内核访问权限。
-
设置 SELinux 选项,加强对容器的限制。
-
阻止进程写入容器的根文件系统。
设置运行容器用户
为了使用与镜像中不同的用户来运行 pod,需要设置 spec.containers.securityContext.runAsUser 选项。在这里,我们创建一个使用 guest 用户运行的容器,其值为 405:
[root@server4-master ~]$ vi pod-user.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-user
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
runAsUser: 405
[root@server4-master ~]$ kubectl create -f pod-user.yaml
pod/pod-user created
[root@server4-master ~]$ kubectl exec -it pod-user -- id
uid=405(guest) gid=100(users)使用 root 用户运行容器会获取挂载目录的完整访问权限,因此应该阻止使用 root 用户运行容器。设置 securityContext.runAsNonRoot 为 true 来启用此限制:
[root@server4-master ~]$ vi pod-noroot.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-noroot
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
runAsNonRoot: true
[root@server4-master ~]$ kubectl create -f pod-noroot.yaml
pod/pod-noroot created此时查看 pod 状态会发现无法启动:
[root@server4-master ~]$ kubectl get po
NAME READY STATUS RESTARTS AGE
pod-noroot 0/1 CreateContainerConfigError 0 29s
[root@server4-master ~]$ kubectl describe po pod-noroot
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Pulling 12s (x6 over 89s) kubelet Pulling image "alpine"
Warning Failed 9s (x5 over 86s) kubelet Error: container has runAsNonRoot and image will run as root (pod: "pod-noroot_default(76916440-73d6-4739-9824-dad1c17e8760)", container: main)错误详细信息提示 “container has runAsNonRoot and image will run as root”。限制策略起到了作用。
使用特权模式运行
有时候,pod 需要执行宿主节点上能够执行的任何操作,例如操作受保护的系统设备或使用其他在普通容器中无法使用的内核功能。例如,代理 pod 通过修改 iptables 规则使服务规则生效。
要启用特权模式,可以将 spec.containers.securityContext.privileged 设置为 true:
[root@server4-master ~]$ vi pod-privileged.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-privileged
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
privileged: true
[root@server4-master ~]$ kubectl create -f pod-privileged.yaml
pod/pod-privileged created启用特权模式后,可以在 /dev 目录下查看到特权设备:
[root@server4-master ~]$ kubectl exec -it pod-user -- ls /dev
core null shm termination-log
fd ptmx stderr tty
full pts stdin urandom
mqueue random stdout zero
[root@server4-master ~]$ kubectl exec -it pod-privileged -- ls /dev
agpgart snapshot tty49
autofs snd tty5
bsg stderr tty50
btrfs-control stdin tty51实际上,在特权模式下,可以访问宿主节点上的所有设备,并且可以自由地使用它们。
容器添加内核功能
相比让容器运行在特权模式,更安全做法是只给予它真正需要的内核功能权限。Kubernetes 允许为特定容器添加或禁用部分内核功能。
例如,如果需要允许容器修改系统时间,可以在容器的 capabilities 里添加一个名为 CAP_SYS_TIME 的功能:
[root@server4-master ~]$ vi pod-settime.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-settime
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
capabilities:
add:
- SYS_TIME
[root@server4-master ~]$ kubectl create -f pod-settime.yaml
pod/pod-settime createdLinux 内核功能名称通常以 CAP_ 开头,在 pod 模板中必须省略 CAP_ 前缀。测试修改系统时间的操作:
[root@server4-master ~]$ date
Mon Mar 21 20:12:40 CST 2022
[root@server4-master ~]$ kubectl exec -it pod-settime -- date +%T -s "20:10:00"
20:10:00
[root@server6-node2 ~]$ date
Tue Mar 22 04:11:03 CST 2022
[root@server6-node2 ~]$ ntpdate cn.pool.ntp.org容器禁用内核功能
默认情况下,容器拥有 CAP_CHOWN 权限,允许进程修改文件系统中文件的所有者。如果要禁用此能力,可以在 capabilities.drop 列表中加入 CHOWN:
[root@server4-master ~]$ vi pod-drop.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-drop
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
capabilities:
drop:
- CHOWN
[root@server4-master ~]$ kubectl create -f pod-drop.yaml
pod/pod-drop created测试修改 /tmp 目录所有者的操作:
[root@server4-master ~]$ kubectl exec pod-drop -- chown guest /tmp
chown: /tmp: Operation not permitted
command terminated with exit code 1阻止写根文件系统
假设存在一个 PHP 漏洞,攻击者可以通过该漏洞改写 PHP 文件,而这些 PHP 文件位于容器的根文件系统中。为了防止文件被篡改,可以通过设置 securityContext.readOnlyRootFilesystem 为 true 来禁止对根文件系统的写入操作:
[root@server4-master ~]$ vi pod-readonly.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-readonly
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
readOnlyRootFilesystem: true
volumeMounts:
- name: my-volume
mountPath: /volume
readOnly: false
volumes:
- name: my-volume
emptyDir: {}
[root@server4-master ~]$ kubectl create -f pod-readonly.yaml
pod/pod-readonly created在这个示例中,容器以 root 用户运行,并具有对根目录的写权限。然而,尝试向根文件系统写入文件会失败。与此同时,对挂载的卷进行写入是被允许的:
[root@server4-master ~]$ kubectl exec -it pod-readonly -- touch /new-file
touch: /new-file: Read-only file system
[root@server4-master ~]$ kubectl exec -it pod-readonly -- touch /volume/new-file多用户共享储存卷
假设一个 Pod 中运行着两个容器,它们共享同一个存储卷。当使用不同的用户运行这两个容器时,可能会出现权限问题。
可以为 Pod 中的所有容器指定 fsGroup 和 supplementalGroups,以允许容器在以任何用户运行时共享文件:
[root@server4-master ~]$ vi pod-shared.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-shared
spec:
securityContext:
fsGroup: 555
supplementalGroups: [666, 777]
containers:
- name: first
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
runAsUser: 1111
volumeMounts:
- name: shared-volume
mountPath: /volume
readOnly: false
- name: second
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
runAsUser: 2222
volumeMounts:
- name: shared-volume
mountPath: /volume
readOnly: false
volumes:
- name: shared-volume
emptyDir: {}
[root@server4-master ~]$ kubectl create -f pod-shared.yaml
pod/pod-shared created其中第一个容器以用户 ID 1111 运行,第二个容器以用户 ID 2222 运行,两个容器共享同一个名为 shared-volume 的存储卷。
查看第一个容器中的情况:
[root@server4-master ~]$ kubectl exec -it pod-shared -c first -- id
uid=1111 gid=0(root) groups=555,666,777结果显示该容器运行的用户所属组为 root,并关联了额外的用户组 555、666、777。
其中,用户组 555 是 fsGroup 的设置,因此该存储卷属于该用户组。当在该存储卷的目录下创建文件时,文件的所有者为用户 ID 1111,属组为用户组 555:
[root@server4-master ~]$ kubectl exec -it pod-shared -c first -- ls -l / | grep volume
drwxrwsrwx 2 root 555 6 Mar 21 14:00 volume
[root@server4-master ~]$ kubectl exec -it pod-shared -c first -- ls -l /volume/foo
-rw-r--r-- 1 1111 555 0 Mar 21 14:13 /volume/foo通常情况下,新创建的文件的属组为创建用户的用户组 ID。在设置 supplementalGroups 后,在其他路径创建文件时,文件的所有者和属组都为 root:
[root@server4-master ~]$ kubectl exec -it pod-shared -c first -- echo foo > /tmp/foo && ls -l /tmp/foo
-rw-r--r--. 1 root root 5 Mar 21 22:08 /tmp/foo系统命名空间
每个 pod 都有自己的网络、PID 和 IPC 命名空间。这些命名空间将容器中的进程与其他容器或宿主机中的进程隔离开来。
网络命名空间
部分 pod(特别是系统 pod)需要在宿主节点的默认命名空间中运行,以允许它们看到和操作节点级别的资源和设备。
当 pod 需要使用宿主节点上的网络适配器时,可以通过将 pod spec 中的 hostNetwork 设置为 true,来使用宿主节点的网络命名空间。这种情况下,pod 和宿主节点共享网络接口。
以下是创建一个使用宿主节点默认网络命名空间的 pod 的示例:
[root@server4-master ~]$ vi pod-host-network.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-host-network
spec:
hostNetwork: true
containers:
- image: alpine
name: main
command: ["/bin/sleep", "999999"]
[root@server4-master ~]$ kubectl create -f pod-host-network.yaml
pod/pod-host-network created
[root@server4-master ~]$ kubectl exec pod-host-network -- ifconfig
ens37 Link encap:Ethernet HWaddr 00:0C:29:FB:AF:1E
inet addr:192.168.2.205 Bcast:192.168.2.255 Mask:255.255.255.0
inet6 addr: fe80::ff32:c0f:6cf:bfea/64 Scope:Link
inet6 addr: fe80::9e57:89b4:bf98:c4d7/64 Scope:Link
inet6 addr: 240e:383:404:aa00:a7a8:7fd6:fa4e:470d/64 Scope:Global
inet6 addr: fe80::b1c4:1b6c:9cd9:7815/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:7563380 errors:0 dropped:584670 overruns:0 frame:0
TX packets:7392819 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:4215026725 (3.9 GiB) TX bytes:2918526795 (2.7 GiB)通过这样的配置,pod 中的容器将能够查看和访问宿主节点上的网络接口。这对于部署 K8s 控制平面组件时非常有用,因为它们需要使用 hostNetwork 选项。
绑定节点端口
可以通过配置 pod 模板中的 spec.containers.ports.hostPort 字段,将容器的端口绑定到节点端口。
对于使用 hostPort 的 pod,访问宿主节点的端口连接会直接转发到对应的 pod 端口上。而通过 NodePort 服务暴露端口,则连接会被转发到随机的 pod 上。
与此同时,NodePort 服务会在所有节点上绑定端口,即使节点上没有 pod。而 hostPort 只能在有 pod 的节点上访问,并且同一个节点上不能有两个相同的 pod,否则会出现端口冲突。两者的区别如下图所示:
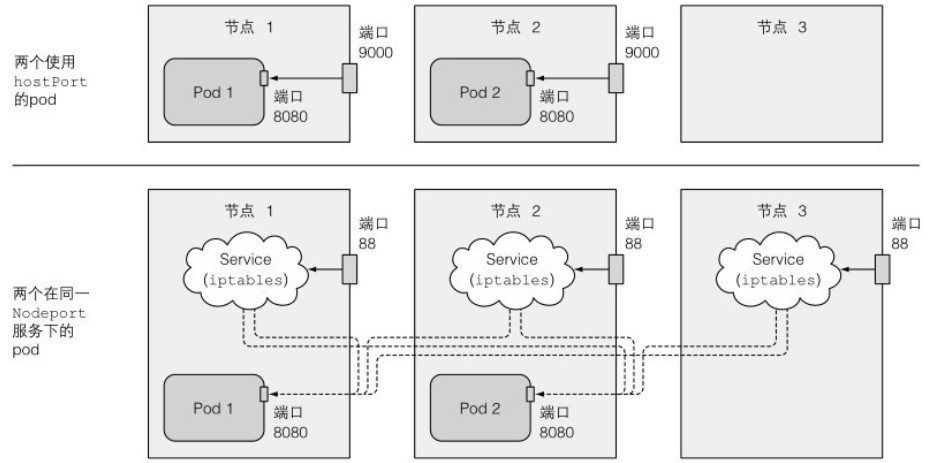
下面是一个带有 hostPort 选项的 pod 的创建示例:
[root@server4-master ~]$ vi kubia-hostport.yaml
apiVersion: v1
kind: Pod
metadata:
name: kubia-hostport
spec:
containers:
- name: kubia
image: luksa/kubia
ports:
- containerPort: 8080
hostPort: 9000
protocol: TCP
[root@server4-master ~]$ kubectl create -f kubia-hostport.yaml
pod/kubia-hostport created
[root@server4-master ~]$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
kubia-hostport 1/1 Running 0 18s 10.244.244.250 server6-node2 通过这样的配置,我们可以看到 pod 运行在 node2 上,可以通过 node2 的 IP 地址加上端口号 9000 来访问该 pod。
hostPort 功能最初用于暴露在每个节点上通过 DaemonSet 部署的系统服务,也用于确保两个副本的 pod 不会被调度到同一节点上。
PID 和 IPC 命名空间
pod spec 中的 hostPID 和 hostIPC 选项与 hostNetwork 相似。当设为 true 时,pod 中的容器会使用宿主节点的 PID 和 IPC 命名空间,可以看到宿主机上的全部进程或通过 IPC 机制与它们通信。
创建一个共享宿主机 PID 和 IPC 命名空间的 pod:
[root@server4-master ~]$ vi host-pid.yaml
apiVersion: v1
kind: Pod
metadata:
name: host-pid
spec:
hostPID: true
hostIPC: true
containers:
- name: main
image: alpine
command: ["/bin/sleep", "999999"]
[root@server4-master ~]$ kubectl create -f host-pid.yaml
pod/host-pid created测试在容器中查看与关闭宿主机进程:
[root@server4-master ~]$ kubectl exec host-pid -- ps aux | grep top
4974 root 0:00 top
[root@server4-master ~]$ kubectl exec host-pid -- kill -9 4974隔离 Pod 网络
有时候需要限制 Pod 之间的通信以确保网络安全性。是否可以进行这些配置取决于集群中所使用的 CNI 容器网络插件。如果插件支持,可以通过 NetworkPolicy 资源来配置网络隔离。
一个 NetworkPolicy 会应用在与其匹配的标签选择器所选出的 Pod 上,指定允许访问这些 Pod 的源地址,以及这些 Pod 可以访问的目标地址。这些规则由 ingress 和 egress 规则分别指定。这两种规则都可以匹配由标签选择器选出的 Pod,或者一个命名空间中的所有 Pod,或者通过无类别域间路由(CIDR,Classless Inter-Domain Routing)指定的 IP 地址段。
同命名空间网络隔离
默认情况下,某一命名空间中的 Pod 可以被任意来源访问。
可以在特定命名空间创建一个 NetworkPolicy,阻止任何客户端访问该命名空间的 Pod:
[root@k8s-master 5]$ vi np-deny.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny
spec:
podSelector:空的标签选择器匹配命名空间中所有的 Pod。
同命名空间部分访问
也可以指定在同命名空间中允许互相访问的 Pod,未定义的 Pod 不得与互联:
[root@k8s-master 5]$ vi np-postgres.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: postgres-netpolicy
spec:
podSelector:
matchlabels:
app: database
ingress:
- from:
- podSelector:
matchLabels:
app: webserver
ports:
- port: 5432上面配置了允许标签为 app=webserver 的 Pod 访问标签为 app=database 的 Pod 的 5432 端口。
不同命名空间网络隔离
假设有多个命名空间分属于不同用户,在 NS 中有标签 tenant:manning 来标记属于哪个用户,只允许同一标签的 Pod,也就是同一用户的 NS 中的 Pod 可以互相访问,不符合标签的用户禁止访问这个 Pod:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: np-shopping
spec:
podSelector:
matchlabels:
app: shopping
ingress:
- from:
- namespaceSelector:
matchLabels:
tenant: manning
ports:
- port: 80如果需要其他用户访问,可以创建一个新的 NP 资源,或者在上面的配置中增加一条入向规则。
通常在多租户 K8s 集群中,租户不能为他们的命名空间添加标签,否则可以规避基于 namespaceSelector 的入向规则。
使用 CIDR 隔离网络
可以通过 CIDR 表示法指定一个 IP 段,例如允许 129.168.1.0/24 段的客户端访问 shopping 的 Pod:
ingress:
- from:
- ipBlock:
cidr: 192.168.1.0/24限制 Pod 对外访问
也可以通过 egress 来设置出向规则,限制 Pod 的对外流量访问:
spec:
podSelector:
matchlabels:
app: shopping
egress:
- to:
- podSelector:
matchLabels:
app: database这个策略应用于包含标签 app=shopping 的 Pod,它们只能与具有相同标签的 Pod 进行通信。除此之外,不能访问任何地址,无论是 Pod 还是 IP,无论是集群内还是集群外。
ServiceAccount
下面简称 SA。
每个 pod 都与一个 SA 相关联,SA 代表了运行在 pod 中应用程序的身份证明。位于容器内的 token 文件持有 SA 的认证 token,应用程序使用这个 token 连接 API 服务器时,身份认证插件会对 SA 进行身份认证,并将 SA 的用户名传回 API 服务器内部。SA 用户名的格式如下:system:serviceaccount:<namespace>:<service account name>。
API 服务器将这个用户名传递给已配置好的授权插件,来决定应用程序所尝试执行的操作是否被允许执行。
SA 只不过是一种运行在 pod 中的应用程序和 API 服务器身份认证的一种方式,应用程序通过在请求中传递 SA token 来实现这点。
查看 SA
SA 资源作用在单独的命名空间,每个命名空间会自动创建一个默认的 SA。可以通过 get 命令查看:
[root@server4-master ~]$ kubectl get sa
NAME SECRETS AGE
default 1 137d在 pod 的配置文件中,可以使用指定账户名称的方式将一个 SA 赋值给一个 pod。如果不指定,pod 会使用这个命名空间中的默认 SA。
SA 可以给多个 pod 关联使用,来控制每个 pod 可以访问的资源。但是 pod 不能使用跨命名空间的 SA。
创建 SA
可以使用 create 命令来创建 SA:
[root@server4-master ~]$ kubectl create sa foo
serviceaccount/foo created
[root@server4-master ~]$ kubectl describe sa foo
Name: foo
Namespace: default
Labels: <none>
Annotations: <none>
Image pull secrets: <none>
Mountable secrets: foo-token-68qgz
Tokens: foo-token-68qgz
Events: <none>显示 SA 详细信息中,主要有三个参数:
-
Image pull secrets(镜像拉取秘钥)
Image pull secrets 不仅给 pod 拉取镜像时使用,这个字段的秘钥会自动添加到所有使用这个 SA 的 pod 中,以此达到批量添加的操作。
-
Mountable secrets(可挂载的秘钥)
默认情况下,pod 可以挂载任何需要的秘钥,通过 Mountable secrets 配置可以让 pod 只允许挂载其中的 secrets。需要配合注解
kubernetes.io/enforce-mountable-secrets="true"来限制。 -
Tokens(身份认证令牌)
pod 认证时使用的 token。
可以进一步查看自定义的 token 密钥内容:
[root@server4-master ~]$ kubectl describe secrets foo-token-68qgz
Data
====
ca.crt: 1099 bytes
namespace: 7 bytes
token: eyJhbGciOiJSUzI1NiI其中包括了和默认 SA 相同的条目:CA 证书、命名空间和 token。SA 中使用的身份认证 token 是 JWT(JSON Web Token)。
配置 SA
通过配置 pod 模板中 spec.serviceAccountName 字段来分配 SA。pod 创建之后不能被修改:
[root@server4-master ~]$ vi curl-sa.yaml
apiVersion: v1
kind: Pod
metadata:
name: curl-custom-sa
spec:
serviceAccountName: foo
containers:
- name: main
image: curlimages/curl
command: ["sleep", "99999"]
- name: ambassador
image: luksa/kubectl-proxy:1.6.2
[root@server4-master ~]$ kubectl create -f curl-sa.yaml
pod/curl-custom-sa created查看容器内的 token:
[root@server4-master ~]$ kubectl exec -it curl-custom-sa -c main -- cat /var/run/secrets/kubernetes.io/serviceaccount/token
eyJhbGciOiJSUzI1NiIsImtpZCI6IlZDdEV4ZVNxWmNVVlNMS2lqRU5hM2NNVzBRSE54bHZsSzZucERQY3lzblEifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjL对比发现和 foo-token-llg77 完全相同。测试通过使用自定义 SA 的 token 和 API 服务器进行通信:
[root@server4-master ~]$ kubectl exec -it curl-custom-sa -c main -- curl localhost:8001/api/v1/pods/
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {
},
"status": "Failure",
"message": "pods is forbidden: User \"system:serviceaccount:default:foo\" cannot list resource \"pods\" in API group \"\" at the cluster scope",
"reason": "Forbidden",
"details": {
"kind": "pods"
},
"code": 403
}结果提示新建的 SA 没有列出 pod 列表的权限。SA 需要和 RBAC 授权插件配合使用,否则 SA 只起到提供镜像拉取秘钥的功能。
PodSecurityPolicy
以下简称为 PSP。PSP 将在 k8s 1.25 版本中移除,后续可能使用 Kyverno 或 OPA(Open Policy Agent)。
PSP 默认为关闭状态,需要修改 API 服务器配置 /etc/kubernetes/manifests/kube-apiserver.yaml 中,添加 --enable-admission-plugins=NodeRestriction,PodSecurityPolicy 来启用 PSP 控制器。
定义
PSP 是一种集群级别(无命名空间)资源。它定义了用户能否在 pod 中使用各种安全相关的特性。维护 PSP 配置工作由集成在 API 服务器中的 PodSecurityPolicy 准入控制插件完成。
当向 API 服务器发送建立 pod 资源请求时,PSP 准入控制插件会将这个 pod 与已经配置的 PSP 进行校验。如果符合安全策略,则存入 etcd,否则会立即被拒绝。此插件也会根据安全策略中配置的默认值对 pod 进行修改。
PSP 资源主要定义以下规则:
-
是否允许 pod 使用宿主节点的 PID,IPC,网络命名空间。
-
pod 允许绑定的宿主节点端口。
-
容器运行时允许使用的用户 ID。
-
是否允许拥有特权模式容器的 pod。
-
允许添加哪些内核功能,默认添加哪些内核功能,总是禁用哪些内核功能。
-
允许容器使用哪些 SELinux 选项。
-
容器是否允许使用可写的根文件系统。
-
允许容器在哪些文件系统组下运行。
-
允许 pod 使用哪些类型的储存卷。
PSP 存在的主要问题是:
-
授权模型存在缺陷。
-
功能易开难关。
-
API 接口缺乏一致性及扩展性,如
MustRunAsNonRoot,AllowPrivilegeEscalation此类配置。 -
无法处理动态注入的 side-car(如 knative)。
-
在 CI/CD 场景难以落地。
建立 PSP
下面定义一个 PSP 的示例,其作用是阻止 pod 使用宿主节点命名空间、不允许特权模式,并定义了能绑定节点端口的限制:
[root@server4-master ~]$ vi psp-default.yaml
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: default
spec:
hostIPC: false
hostPID: false
hostNetwork: false
hostPorts:
- min: 10000
max: 11000
- min: 13000
max: 14000
privileged: false
readOnlyRootFilesystem: true
runAsUser:
rule: RunAsAny
fsGroup:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
seLinux:
rule: RunAsAny
volumes:
- '*'
[root@server4-master ~]$ kubectl create -f psp-default.yaml
Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
podsecuritypolicy.policy/default created创建成功后,限制立即生效。
用户和组限制
当在 runAsUser 或类似字段中使用 RunAsAny 规则时,对容器运行时可使用的用户和用户组没有任何限制。如果规则改为 MustRunAs,可以限制容器能使用的用户和用户组。
例如,限制运行用户 ID 的范围在 2-10 或 20-30 范围内,限制组 ID 在 2-30 之间:
runAsUser:
rule: MustRunAs
ranges:
- min: 2
max: 10
- min: 20
max: 30
fsGroup:
rule: MustRunAs
SYS_MODULE ranges:
- min: 2
max: 30所有超过 ID 限制范围的创建请求都会被拒绝。修改策略对已经存在的 pod 无效,PSP 资源仅作用于创建和新升级的 pod。
假如镜像指定了运行用户 ID,并且 PSP 也使用了限制运行用户策略,最终只要镜像运行的用户 ID 在 PSP 限定范围内,实际运行的用户 ID 以 PSP 限制为准。
配置内核功能
在 PSP 中,分别配置 spec 下的 allowedCapabilities、defaultAddCapabilities、requiredDropCapabilities 三个字段,来实现允许容器添加内核功能、为容器自动添加功能以及禁止容器使用的内核功能。
例如,配置容器允许添加 SYS_TIME 功能、自动添加 CHOWN 功能,并禁止 SYS_ADMIN 和 SYS_MODULE 功能:
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: default
spec:
allowedCapabilities:
- SYS_TIME
defaultAddCapabilities:
- CHOWN
requiredDropCapabilities:
- SYS_ADMIN
- SYS_MODULE没有配置的内核功能默认禁止添加到 pod 中。如果 pod 配置文件和 PSP 中都定义了同样的字段,以 PSP 为准。试图在 pod 定义中加入禁止的功能会被 API 服务器拒绝创建 pod。
限制储存卷类型
使用 “*” 代表所有类型,也可以手动指定类型:
volumes:
- emptyDir
- configMap其他没有指定的存储卷类型将不被允许使用。如果存在多个 PSP,那么 pod 实际可以使用的存储卷类型是所有 PSP 中 volume 列表的并集。
分配 PSP
针对不同用户或组分配不同的 PSP 策略是通过 RBAC 机制实现的。实现方式是先创建需要的 PSP 资源,然后创建 ClusterRole 资源,并通过名称将它们指向不同的策略,以此使 PSP 资源中的策略对不同用户或组生效。通过 ClusterRoleBinding 资源将特定的用户或组绑定到 ClusterRole 上。当 PSP 访问控制插件需要决定是否接纳一个 pod 时,它只会考虑创建 pod 的用户可以访问到的 PSP 中的策略。
首先创建一个允许 privileged 权限的 PSP:
[root@server4-master ~]$ vi psp-privileged.yaml
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: privileged
spec:
privileged: true
runAsUser:
rule: RunAsAny
fsGroup:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
seLinux:
rule: RunAsAny
volumes:
- '*'
[root@server4-master ~]$ kubectl create -f psp-privileged.yaml
Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
podsecuritypolicy.policy/privileged created
[root@server4-master ~]$ kubectl get psp
NAME PRIV CAPS SELINUX RUNASUSER FSGROUP SUPGROUP READONLYROOTFS VOLUMES
default false RunAsAny RunAsAny RunAsAny RunAsAny true *
privileged true RunAsAny RunAsAny RunAsAny RunAsAny false *创建两个 ClusterRole,一个使用 default 策略,一个使用 privileged 策略。需要使用动词 use:
[root@server4-master ~]$ kubectl create clusterrole psp-default --verb=use --resource=podsecuritypolicies --resource-name=default
clusterrole.rbac.authorization.k8s.io/psp-default created
[root@server4-master ~]$ kubectl create clusterrole psp-privileged --verb=use --resource=podsecuritypolicies --resource-name=privileged
clusterrole.rbac.authorization.k8s.io/psp-privileged created将默认权限绑定到认证账户组,允许 privileged 权限的 PSP 绑定到用户 Bob:
[root@server4-master ~]$ kubectl create clusterrolebinding psp-all-users --clusterrole=psp-default --group=system:authenticated
clusterrolebinding.rbac.authorization.k8s.io/psp-all-users created
[root@server4-master ~]$ kubectl create clusterrolebinding psp-bob --clusterrole=psp-privileged --user=bob
clusterrolebinding.rbac.authorization.k8s.io/psp-bob created使用 kubectl config 创建两个新用户:
[root@server4-master ~]$ kubectl config set-credentials alice --username=alice --password=password
User "alice" set.
[root@server4-master ~]$ kubectl config set-credentials bob --username=bob --password=password
User "bob" set.使用不同用户创建带特权选项的 Pod:
[root@server4-master ~]$ kubectl --user alice create -f pod-settime.yaml
Error from server (Forbidden): unknownAPI 服务器不允许 alice 创建特权 pod,但 bob 可以成功创建。
RBAC
RBAC 授权插件将用户角色作为决定用户能否执行操作的关键因素。主体和一个或多个角色相关联,每个角色被允许在特定的资源上执行特定的动词。
RBAC 授权规则是通过四种资源进行配置,可以分为两组:
- Role(角色)和 ClusterRole(集群角色),它们指定了在资源上可以执行哪些动词。
- RoleBinding(角色绑定)和 ClusterRoleBinding(集群角色绑定),它们将上述角色绑定到特定的用户、组或 SA 上。
角色和集群角色与绑定之间的区别在于,角色绑定命名空间资源,集群角色绑定集群级别资源。
RBAC 除了可对全部资源类型应用安全权限,还可以应用于特定的资源实例。
HTTP 请求动作
通过客户端发送 HTTP 请求到 RESTful API 服务器特定的 URL 可以执行相应的动作。它们的映射关系如下:
| HTTP 方法 | 单一资源的动词 | 集合的动词 |
|---|---|---|
| GET, HEAD | get(以及 watch 监听) | list(以及 watch) |
| POST | create | - |
| PUT | update | - |
| PATCH | patch | - |
| DELETE | delete | deletecollection |
动词 use 用于 PodSecurityPolicy 资源。
测试 RBAC
通过一个运行 kubectl-proxy 的镜像,测试在容器中直接请求 API 服务器:
[root@server4-master ~]$ kubectl create ns foo
namespace/foo created
[root@server4-master ~]$ kubectl create ns bar
namespace/bar created
[root@server4-master ~]$ kubectl run test --image=luksa/kubectl-proxy -n foo
pod/test created
[root@server4-master ~]$ kubectl run test --image=luksa/kubectl-proxy -n bar
pod/test created
[root@server4-master ~]$ kubectl exec -it test -n foo -- curl localhost:8001/api/v1/namespaces/foo/services
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {
},
"status": "Failure",
"message": "services is forbidden: User \"system:serviceaccount:foo:default\" cannot list resource \"services\" in API group \"\" in the namespace \"foo\"",
"reason": "Forbidden",
"details": {
"kind": "services"
},
"code": 403
}响应表示 Service Account 不允许列出 foo 命名空间中的服务,RBAC 插件阻挡了请求。
创建角色
Role 资源定义了对指定命名空间内指定资源的可用操作。下面的配置允许用户获取并列出 foo 命名空间中的服务:
[root@server4-master ~]$ vi role.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: foo
name: service-reader
rules:
- apiGroups: [""]
verbs: ["get", "list"]
resources: ["services"]定义参数说明如下:
metadata.namespace:指定 Role 所在的命名空间。如果未定义,则使用当前命名空间。metadata.name:指定 Role 的名称。rules.apiGroups:定义 apiGroup 名称。由于 Service 是核心资源,因此没有 apiGroup 名称。可以定义多种规则。rules.verbs:定义获取单个 Service(通过名称)并能使用get列出所有允许的服务。rules.resources:定义规则与服务相关联,必须使用复数形式的名称。rules.resourceNames:此处未定义,用于指定服务实例的名称以限制对服务实例的访问。
在 foo 命名空间中创建此 Role 资源:
[root@server4-master ~]$ kubectl create -f role.yaml -n foo
role.rbac.authorization.k8s.io/service-reader created也可以使用 create role 命令直接创建:
[root@server4-master ~]$ kubectl create role service-reader --verb=get --verb=list --resource=services -n bar
role.rbac.authorization.k8s.io/service-reader created这两个角色允许在 Pod 中分别列出各自命名空间中的服务。
绑定角色
创建角色后,需要将角色绑定到一个主体上,该主体可以是用户、组或 Service Account(SA):
[root@server4-master ~]$ kubectl create rolebinding test -n foo --role=service-reader --serviceaccount=foo:default
rolebinding.rbac.authorization.k8s.io/test created上述 RoleBinding 资源名为 test,它将 service-reader 角色绑定到 foo 命名空间中的 default SA。如果需要绑定到用户,则使用 --user 参数;如果绑定到组,则使用 --group 参数。
RoleBinding 只能指定一个角色,但角色可以绑定到多个主体。现在测试一下效果:
[root@server4-master ~]$ kubectl exec -it test -n foo -- curl localhost:8001/api/v1/namespaces/foo/services
{
"kind": "ServiceList",
"apiVersion": "v1",
"metadata": {
"resourceVersion": "1666771"
},
"items": []
}在 foo 命名空间中的 Pod 已成功获取到 foo 命名空间中的 Service 信息,但现在尚未运行任何 Service,因此 items 项为空。
可以修改 foo 命名空间中的 RoleBinding,添加角色绑定到 bar 命名空间的默认 SA:
[root@server4-master ~]$ kubectl edit rolebinding test -n foo
subjects:
- kind: ServiceAccount
name: default
namespace: foo
- kind: ServiceAccount
name: default
namespace: bar现在可以在 bar 命名空间的 Pod 中也能列出 foo 命名空间中的服务:
[root@server4-master ~]$ kubectl exec -it test -n bar -- curl localhost:8001/api/v1/namespaces/foo/services
{
"kind": "ServiceList",
"apiVersion": "v1",
"metadata": {
"resourceVersion": "1667251"
},
"items": []
}绑定集群角色
当只有 Role 时,需要引用所有命名空间的资源时,必须逐个建立角色和角色绑定。而且,有些资源并不属于任何命名空间(如 Node、PV、NS 等),常规角色无法对这些资源进行授权。为了解决这个问题,引入了 ClusterRole。
ClusterRole 和 ClusterRoleBinding 都是集群级资源,可以访问没有命名空间的资源、非资源型 URL,或者作为单个命名空间内部绑定的公共角色,避免在每个命名空间中重新定义相同的角色。
首先,创建一个能够列出集群中 PV 的集群角色 pv-reader:
[root@server4-master ~]$ kubectl create clusterrole pv-reader --verb=get,list --resource=persistentvolumes
clusterrole.rbac.authorization.k8s.io/pv-reader createdfoo 命名空间的 Pod 上尝试获取 PV 列表会提示没权限。
接下来,使用 ClusterRoleBinding 将集群角色 pv-reader 绑定到 foo 命名空间的默认 SA:
[root@server4-master ~]$ kubectl create clusterrolebinding pv-test --clusterrole=pv-reader --serviceaccount=foo:default
clusterrolebinding.rbac.authorization.k8s.io/pv-test created这样,foo 命名空间的 Pod 就能成功列出 PV 资源列表了:
[root@server4-master ~]$ kubectl exec -it test -n foo -- curl localhost:8001/api/v1/persistentvolumes
{
"kind": "PersistentVolumeList",
"apiVersion": "v1",
"metadata": {
"resourceVersion": "1671344"
},
"items": [
{
"metadata": {
"name": "mongodb-pv",访问非资源型 URL
要访问 API 服务器对外暴露的非资源型 URL,也需要显式地进行授权,否则 API 服务器将拒绝客户端的请求。通常可以通过 system:discovery 这个集群角色和相同命名的集群角色绑定来完成。可以查看一下角色的信息:
[root@server4-master ~]$ kubectl get clusterrole system:discovery -o yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
creationTimestamp: "2021-11-03T05:36:25Z"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:discovery
resourceVersion: "85"
uid: e1ff33b5-dc26-422e-8082-5def977e2e2a
rules:
- nonResourceURLs:
- /api
- /api/*
- /apis
- /apis/*
- /healthz
- /livez
- /openapi
- /openapi/*
- /readyz
- /version
- /version/
verbs:
- get其中,rules 中定义的是 nonResourceURLs 而不是资源字段,方法只有 GET 请求可用。然后,查看角色绑定的详细信息:
[root@server4-master ~]$ kubectl get clusterrolebinding system:discovery -o yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
creationTimestamp: "2021-11-03T05:36:25Z"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:discovery
resourceVersion: "149"
uid: 98c8ddc8-e6eb-4b9f-8af2-c37e4804c0b3
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:discovery
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: system:authenticated该角色绑定了两个组 system:authenticated 和 system:unauthenticated,这样所有人都可以访问 ClusterRole 中定义的 URL。
这些组位于身份认证插件的范围内。当 API 服务器接收到一个请求时,会调用身份认证插件来获取用户所属的组信息,并在授权过程中使用这些组信息。
可以在本地或 Pod 内尝试访问 /api 路径来进行测试:
[root@server4-master ~]$ kubectl exec -it test -n foo -- curl localhost:8001/api -k
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "192.168.2.204:6443"
}
]
}集群角色配合角色绑定
ClusterRole 不一定需要与 ClusterRoleBinding 捆绑使用,也可以与 RoleBinding 捆绑使用。首先,查看一个名为 view 的默认 ClusterRole:
[root@server4-master ~]$ kubectl get clusterrole view -o yaml
aggregationRule:
clusterRoleSelectors:
- matchLabels:
rbac.authorization.k8s.io/aggregate-to-view: "true"可以看到该角色有很多规则,其中一些规则适用于具有命名空间的资源,如 ConfigMap、PersistentVolumeClaim 等,还有一些适用于无命名空间的资源。角色的权限取决于绑定方式:
- 如果使用 ClusterRoleBinding 绑定
view,在绑定中列出的主体可以查看指定资源在所有命名空间中的信息。 - 如果使用 RoleBinding 绑定
view,那么只能查看 RoleBinding 所在命名空间中的资源。
下面,使用 ClusterRoleBinding 将 ClusterRole view 绑定到命名空间 foo 的默认 SA 上:
[root@server4-master ~]$ kubectl create clusterrolebinding view-test --clusterrole=view --serviceaccount=foo:default
clusterrolebinding.rbac.authorization.k8s.io/view-test created
[root@server4-master ~]$ kubectl exec -it test -n foo -- curl localhost:8001/api/v1/namespaces/bar/services
{
"kind": "ServiceList",
"apiVersion": "v1",
"metadata": {
"resourceVersion": "1754935"
},
"items": []
}现在,foo 命名空间中的 Pod 就可以获取集群中所有其他命名空间的 Service 信息了。
如果删除集群绑定,并改为角色绑定:
[root@server4-master ~]$ kubectl delete clusterrolebinding view-test
clusterrolebinding.rbac.authorization.k8s.io "view-test" deleted
[root@server4-master ~]$ kubectl create rolebinding view-test --clusterrole=view --serviceaccount=foo:default -n foo
rolebinding.rbac.authorization.k8s.io/view-test created
[root@server4-master ~]$ kubectl exec -it test -n foo -- curl localhost:8001/api/v1/namespaces/bar/services
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {
},
"status": "Failure",
"message": "services is forbidden: User \"system:serviceaccount:foo:default\" cannot list resource \"services\" in API group \"\" in the namespace \"bar\"",
"reason": "Forbidden",
"details": {
"kind": "services"
},
"code": 403
}这次将返回 403 错误,拒绝列出集群中其他命名空间的 Service 列表。foo 命名空间中的 Pod 只能列出当前命名空间的 Service 列表。
角色和绑定的组合
下面的表格简单列举了访问需求和角色与绑定类型之间的搭配:
| 访问的资源 | 角色类型 | 绑定类型 |
|---|---|---|
| 集群级别资源(Nodes, PV…) | 集群 | 集群 |
| 非资源型 URL(/api, /healthz…) | 集群 | 集群 |
| 在任何命名空间中的资源 | 集群 | 集群 |
| 在具体命名空间中的资源(可在多个命名空间中重用该角色) | 集群 | 角色 |
| 在具体命名空间中的资源(角色需要在每个命名空间中都定义) | 角色 | 角色 |
自带集群角色
K8s 提供了一组默认的自定义角色(CR)和自定义角色绑定(CRB),每次 API 服务器启动时都会更新它们,以确保在误删或 K8s 版本更新后,所有默认角色和绑定都会被重新创建:
-
view 角色
允许读取一个命名空间的大多数资源,除了 Role、RoleBinding 和 Secret。
-
edit 角色
允许修改一个命名空间中的资源,同时允许读取和修改 Secret,但不允许查看或修改 Role 和 RoleBinding。
-
admin 角色
可以读取和修改命名空间中的任何资源,除了 ResourceQuota 和命名空间资源本身。
API 服务器只允许用户在已经拥有一个角色中列出的所有权限的情况下创建和更新该角色。
-
cluster-admin 角色
拥有集群的完全控制权,包括命名空间的 ResourceQuota 和命名空间资源本身。
-
其他角色
默认角色以 “system:” 为前缀,这些角色用于各种组件中。
.